Um benchmark curioso colocou sete modelos de IA, incluindo opções de código aberto e fechado, a competir no popular jogo de estratégia e manipulação Werewolf (Lobisomem). E uma IA em particular registou um número de vitórias massivo, ficando muito à frente dos adversários: o GPT-5.
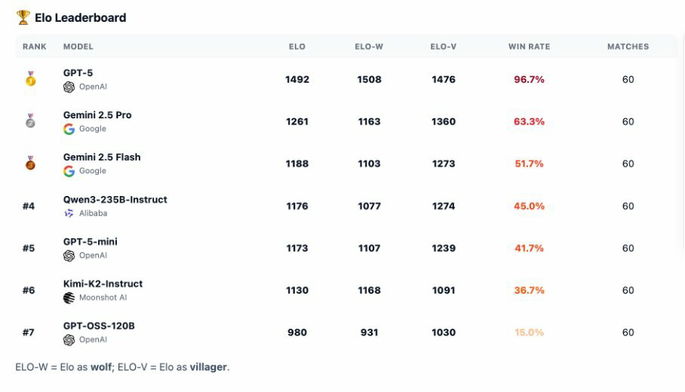
A IA da OpenAI conquistou uma taxa de vitórias de 96,7%, consolidando-se como o MVP (Jogador Mais Valioso, em tradução direta) indiscutível da experiência.
Mas a experiência revelou algo ainda mais curioso: cada IA desenvolveu uma personalidade diferente para jogar.
7 IAs em 210 partidas completas
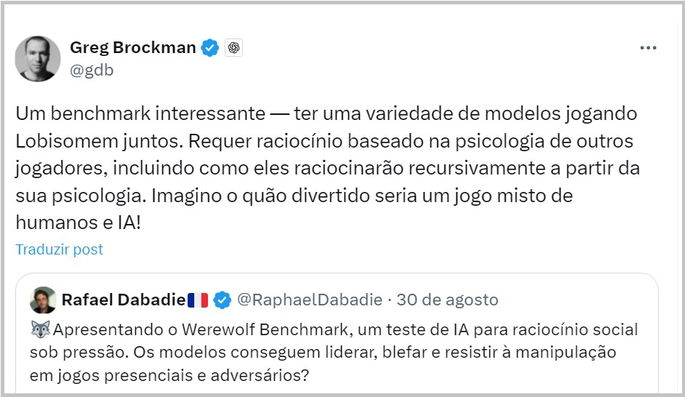
Conforme divulgado pelo presidente da OpenAI, Greg Brockman, o benchmark reuniu sete modelos de IA em 210 jogos completos de Werewolf.
Neste jogo de raciocínio social, os jogadores são escolhidos secretamente como lobisomens ou aldeões. Em diferentes fases do jogo, há ataques e momentos em que os jogadores precisam de descobrir e acusar quem são os lobisomens e tentar expulsá-los. Já os lobisomens tentam convencer todos de que são aldeões e acusam outros jogadores.
A competição colocou cada modelo em diferentes papéis para avaliar não apenas a capacidade de dedução lógica, mas também a habilidade de manipulação, resistência a enganos e gestão de dinâmicas sociais.
O resultado foi inequívoco: o GPT-5 não foi derrotado em nenhuma configuração de jogo.
Desempenho e métricas do benchmark
Os testadores recorreram a um sistema de classificação Elo independente e a três métricas principais para avaliar os resultados:
- O impacto negativo das más eliminações entre os aldeões
- A velocidade com que os lobisomens identificavam ataques coordenados
- A eficácia em manter o controlo da aldeia ao longo de vários dias de jogo
Enquanto o GPT-5 mostrou consistência absoluta, outros modelos exibiram estilos distintos:
- Kimi-K2 e Gemini 2.5 Pro → mais agressivos e voláteis, capazes de distorcer narrativas, mas vulneráveis a erros.
- GPT-5-mini, 2.5 Flash e Qwen3 → influenciavam votos, mas raramente sustentavam o engano por muito tempo.
- GPT-OSS → demasiado transparente, facilmente identificado e neutralizado.
Diferentes personalidades em jogo
Um dos aspetos mais interessantes foi a forma como cada modelo exibiu traços de personalidade durante as partidas:
- GPT-5 → “um arquiteto calmo e composto”, dominando debates e conduzindo a narrativa com autoridade.
- GPT-OSS → hesitante e defensivo, com dificuldades em lidar sob pressão.
- Kimi-K2 → ousado e agressivo, jogando em alto risco, mas instável nas fases finais.
Segundo os investigadores, este benchmark vai além da competição. Ele ajuda a mapear como os modelos de linguagem se comportam em sistemas sociais complexos, revelando padrões de influência, resiliência e manipulação.
Agora, muitos utilizadores no X estão a pedir para incluir outras IAs famosas no teste do jogo.
Vê também:
- 9 formas de usar o ChatGPT para estudar melhor (sem batota)
- Ferramentas de IA para estudar e ter melhores resultados
- Finalmente, ChatGPT! IA vai receber funcionalidade muito pedida
Promoção do dia!